Text Mining w dużych zbiorach danych
W ostatnich latach jednym z głównych obszarów aplikacji do analityki tekstu była analiza predyktywna, wykorzystująca text mining do eksploracji dużych baz danych. Wykorzystując eksplorację tekstów do uczenia się na podstawie historycznych zachowań, odkrywania wzorców i identyfikowania trendów, naukowcy mogą tworzyć prognozy w różnych dziedzinach.
Zapraszamy do zapoznania się z artykułem „Big Data for Prediction: Patent Analysis”.
Analiza patentów z użyciem text mining może pomóc inwestorom i wynalazcom lepiej zrozumieć, w jakim kierunku zmierza dana technologia i pomóc im w podejmowaniu decyzji o niezbędnych inwestycjach lub gdzie należy skoncentrować swoje wysiłki. W swojej pracy autorzy wykorzystali dwa programy do analizy tekstu, jednym z nich była aplikacja WordStat. Poniżej znajdą Państwo krótkie podsumowanie artykułu.
Istnieje wiele baz patentowych na całym świecie i wiele komercyjnych platform patentowych. Autorzy postanowili zbadać patenty z bazy danych PatSeer dotyczące wykorzystania dużych zbiorów danych do analityki predykcyjnej w okresie od roku 2013 do 13 października 2017 r. Analizowano patenty, stosując przekrojowe badania w połączeniu z technikami wydobywania tekstu. Analiza patentowa składa się z czterech etapów związanych z
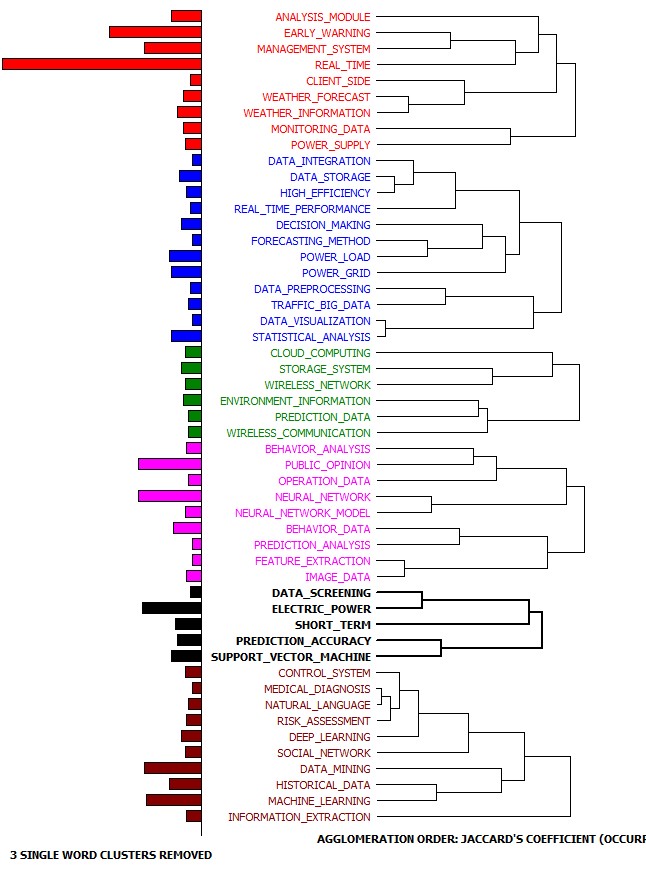
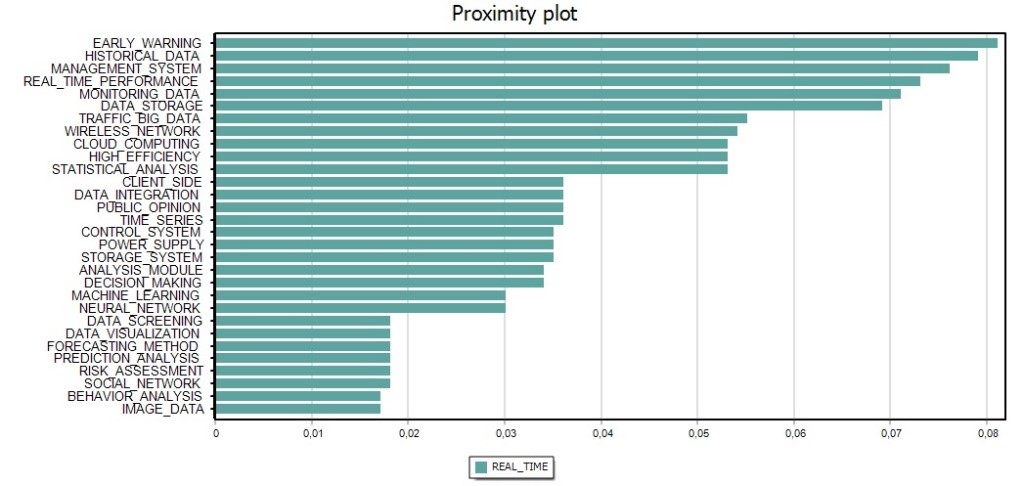
Autorzy wykonali wstępne wyszukiwanie i wybór aktywnych prostych rodzin patentowych, następnie przeanalizowali treść techniczną opartą na systemie międzynarodowej klasyfikacji patentowej (IPC). Następnie został wykorzystany program WordStat, który posłużył do znalezienia zdań składających się z maksymalnie pięciu słów, które wystąpiły w więcej niż pięciu prostych abstraktach patentowych rodziny. Następnie przeprowadzona została analiza skupień, aby znaleźć tematy. Autorzy wykorzystali wykresy bliskości (proximity plots), aby zobaczyć, które zwroty pojawiły się z najczęstszymi i najważniejszymi frazami. Wykorzystano również wykresy sieci klastrów do zbadania połączeń między słowami kluczowymi oraz do wykrycia podstawowych wzorców i struktur współwystępowania.

Po wykonaniu badań autorzy przyjrzeli się pytaniom, na które można odpowiedzieć inwestorom i wynalazcom zainteresowanym rozwiązaniami Big Data w zakresie analizy predykcyjnej oraz w jaki sposób analiza patentu może dostarczyć odpowiedzi na podstawowe pytania, takie jak: kiedy, gdzie, kto i co.
Pełna treść artykułu jest zamieszczona na stronie: https://bit.ly/2sqQ5br
Zapraszamy do zapoznania się z artykułem „Big Data for Prediction: Patent Analysis”.
Analiza patentów z użyciem text mining może pomóc inwestorom i wynalazcom lepiej zrozumieć, w jakim kierunku zmierza dana technologia i pomóc im w podejmowaniu decyzji o niezbędnych inwestycjach lub gdzie należy skoncentrować swoje wysiłki. W swojej pracy autorzy wykorzystali dwa programy do analizy tekstu, jednym z nich była aplikacja WordStat. Poniżej znajdą Państwo krótkie podsumowanie artykułu.
Istnieje wiele baz patentowych na całym świecie i wiele komercyjnych platform patentowych. Autorzy postanowili zbadać patenty z bazy danych PatSeer dotyczące wykorzystania dużych zbiorów danych do analityki predykcyjnej w okresie od roku 2013 do 13 października 2017 r. Analizowano patenty, stosując przekrojowe badania w połączeniu z technikami wydobywania tekstu. Analiza patentowa składa się z czterech etapów związanych z
- wyszukiwaniem i selekcja patentów,
- linią czasową, pochodzeniem geograficznym i analizą cesjonariuszy patentów,
- analizą patentów według patentowego systemu IPC,
- wyszukiwaniem tekstowym do odkrycia tematów najczęściej pojawiających się w abstraktach patentów.
Autorzy wykonali wstępne wyszukiwanie i wybór aktywnych prostych rodzin patentowych, następnie przeanalizowali treść techniczną opartą na systemie międzynarodowej klasyfikacji patentowej (IPC). Następnie został wykorzystany program WordStat, który posłużył do znalezienia zdań składających się z maksymalnie pięciu słów, które wystąpiły w więcej niż pięciu prostych abstraktach patentowych rodziny. Następnie przeprowadzona została analiza skupień, aby znaleźć tematy. Autorzy wykorzystali wykresy bliskości (proximity plots), aby zobaczyć, które zwroty pojawiły się z najczęstszymi i najważniejszymi frazami. Wykorzystano również wykresy sieci klastrów do zbadania połączeń między słowami kluczowymi oraz do wykrycia podstawowych wzorców i struktur współwystępowania.
Po wykonaniu badań autorzy przyjrzeli się pytaniom, na które można odpowiedzieć inwestorom i wynalazcom zainteresowanym rozwiązaniami Big Data w zakresie analizy predykcyjnej oraz w jaki sposób analiza patentu może dostarczyć odpowiedzi na podstawowe pytania, takie jak: kiedy, gdzie, kto i co.
Pełna treść artykułu jest zamieszczona na stronie: https://bit.ly/2sqQ5br