Farmacja
Ilość danych stale wzrasta, z tego powodu wyszukiwanie informacji naukowych w dokumentach w wersji papierowej stało się uciążliwe i czasochłonne. Dlatego pracownicy naukowi z firm komercyjnych potrzebują odpowiedniego oprogramowania do odczytu i analizy danych.
Pomocne do ww. celów są narzędzia typu Text Mining, które umożliwiają przeszukiwanie ogromnej liczby artykułów jednocześnie, celem odkrycia ukrytych powiązań badań i ułatwiają odkrywanie nowych leków. Proste wyszukiwanie potrzebnych danych nie daje obecnie możliwości przeanalizowania dostępnej tak ogromnej liczby informacji. Wykorzystanie metod eksploracji tekstu i danych zwielokrotnia moc tradycyjnej funkcji wyszukiwania, umożliwiając pobieranie i streszczanie tekstów, co znacząco wpływa na szybkość wykonywanych zadań.
Indeksowanie komputerowe jest wykorzystywane głównie ze względu na możliwość szybkiego czytania plików, ale firmy farmaceutyczne odnajdują dla niego dodatkowe zastosowania. Na przykład, aby przeanalizować działania konkurencji można przejść przez pola przynależności artykułów i zobaczyć, które firmy są aktywne w poszczególnych dziedzinach. Następnie można sprawdzić informacje nt. prowadzonych przez te firmy projektów.
Istnieje także możliwość przeszukiwania abstraktów konferencyjnych zawierających nowatorskie informacje, które nie zostały jeszcze opublikowane w literaturze oraz przeczesywania informacji na temat dotacji i patentów. Wykorzystanie narzędzi text minng pozwala także sortować setki plakatów abstraktów konferencyjnych, dzięki czemu użytkownik może dla siebie znaleźć i wybrać najbardziej interesujące sesje. Ułatwia to podjęcie decyzji, w której konferencji warto uczestniczyć, zwłaszcza w przypadku zjazdów naukowych uruchamianych w tym samym czasie.
<6h>Problemy ze stosowaniem metody text mining przez instytucje akademickie Firmy farmaceutyczne dysponują niezbędnymi środkami finansowymi, aby zapłacić za prawa do przeszukiwania literatury w ten sposób. Efektywność metody text miningu jest oczywista, ale publicznie finansowane instytucje naukowe w Europie napotykają na bariery prawne do jej stosowania. W obecnym stanie rzeczy, wydawcy mają prawo do udzielania lub odmowy wydobycia informacji z czasopism naukowych na podstawie prawa autorskiego, europejskiego prawa ochrony baz danych oraz przepisów związanych z prawem własności intelektualnej. Wielka Brytania jest jedynym krajem w Europie, który uwolnił zautomatyzowane wyszukiwanie i wydobywanie komputerowe od prawa autorskiego.
Wydawcy publikacji domyślnie blokują programy eksploracji danych, ale mogą wydać specjalne uprawnienia licencyjne dla środowisk akademickich i bibliotek uniwersyteckich. W związku z tym, przeprowadzono szerszą debatę na temat otwartego dostępu, co zaowocowało zaproponowaniem nowych zasad. W grudniu ubiegłego roku Komisja Europejska zaproponowała projekt ustawy, która umożliwi naukowcom zastosowanie metod text i data mining, jako część szerokiej aktualizacji europejskich przepisów dotyczących prawa autorskiego.
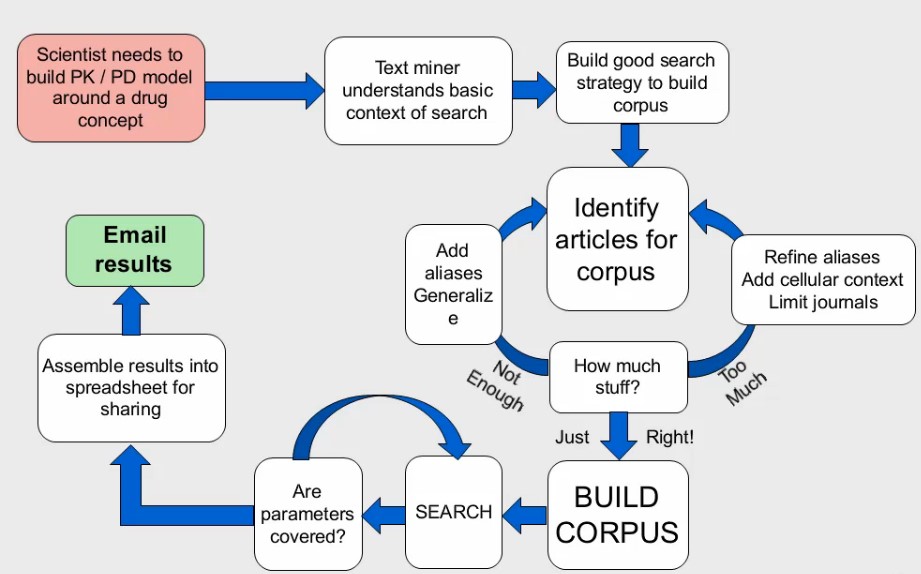
Schemat procesu obróbki danych w text miningu
Źródło: Boehringer Ingelheim Pharmaceutical
Po ustaleniu parametrów można rozpocząć wydobywanie tekstu z wielu różnych źródeł, ale zdecydowanie najbardziej popularnym źródłem jest literatura medyczna.
Naukowcy zwykle będą zainteresowani porównaniem abstraktów. Jednak czasami pełny tekst będzie niezastąpiony, jeśli użytkownik zainteresowany jest wyszukiwaniem większej liczby informacji na temat określonych materiałów i metod. Bardzo kosztowne i czasochłonne jest pobieranie artykułów pełno- tekstowych.
Internet jest przeszukiwany na podstawie wyznaczonego algorytmu wydobycia, a wyniki wyszukiwania są wyświetlane w sformatowanej tabeli z pierwotnego zapytania (lub wydobytych relacji) po lewej stronie i trafiają na prawą stronę. Istnieje również kolumna cytująca, gdzie znaleziono odnośniki.
Wtedy do pracy włącza się naukowiec. Tabela wyznacza wszystkie identyfikatory PubMed z określonych schorzeń oraz identyfikatory genów. Możliwe jest wtedy prześwietlenie danych, aby dowiedzieć się, czy określone choroby są związane z genami, o których mowa w PubMed.
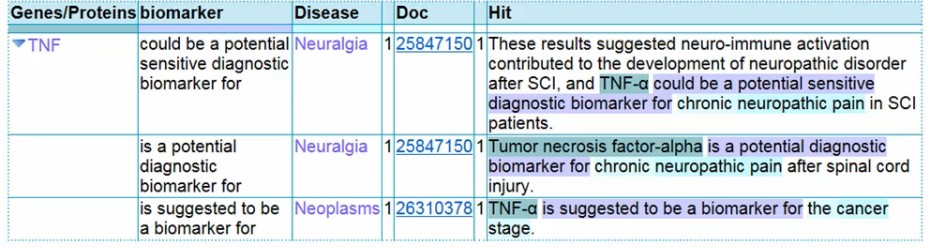
Tabela wynikowa przeszukiwania metodą text mining;
Żródło: Boehringer Ingelheim Pharmaceuticals
Oprogramowanie typu text mining ułatwia pracę naukowcom, jednak jego zastosowanie wymaga także ich wysiłku, gdyż wiele czynności manualnych towarzyszy zautomatyzowanemu wydobyciu tekstu.
Pomocne do ww. celów są narzędzia typu Text Mining, które umożliwiają przeszukiwanie ogromnej liczby artykułów jednocześnie, celem odkrycia ukrytych powiązań badań i ułatwiają odkrywanie nowych leków. Proste wyszukiwanie potrzebnych danych nie daje obecnie możliwości przeanalizowania dostępnej tak ogromnej liczby informacji. Wykorzystanie metod eksploracji tekstu i danych zwielokrotnia moc tradycyjnej funkcji wyszukiwania, umożliwiając pobieranie i streszczanie tekstów, co znacząco wpływa na szybkość wykonywanych zadań.
Indeksowanie komputerowe jest wykorzystywane głównie ze względu na możliwość szybkiego czytania plików, ale firmy farmaceutyczne odnajdują dla niego dodatkowe zastosowania. Na przykład, aby przeanalizować działania konkurencji można przejść przez pola przynależności artykułów i zobaczyć, które firmy są aktywne w poszczególnych dziedzinach. Następnie można sprawdzić informacje nt. prowadzonych przez te firmy projektów.
Istnieje także możliwość przeszukiwania abstraktów konferencyjnych zawierających nowatorskie informacje, które nie zostały jeszcze opublikowane w literaturze oraz przeczesywania informacji na temat dotacji i patentów. Wykorzystanie narzędzi text minng pozwala także sortować setki plakatów abstraktów konferencyjnych, dzięki czemu użytkownik może dla siebie znaleźć i wybrać najbardziej interesujące sesje. Ułatwia to podjęcie decyzji, w której konferencji warto uczestniczyć, zwłaszcza w przypadku zjazdów naukowych uruchamianych w tym samym czasie.
<6h>Problemy ze stosowaniem metody text mining przez instytucje akademickie Firmy farmaceutyczne dysponują niezbędnymi środkami finansowymi, aby zapłacić za prawa do przeszukiwania literatury w ten sposób. Efektywność metody text miningu jest oczywista, ale publicznie finansowane instytucje naukowe w Europie napotykają na bariery prawne do jej stosowania. W obecnym stanie rzeczy, wydawcy mają prawo do udzielania lub odmowy wydobycia informacji z czasopism naukowych na podstawie prawa autorskiego, europejskiego prawa ochrony baz danych oraz przepisów związanych z prawem własności intelektualnej. Wielka Brytania jest jedynym krajem w Europie, który uwolnił zautomatyzowane wyszukiwanie i wydobywanie komputerowe od prawa autorskiego.
Wydawcy publikacji domyślnie blokują programy eksploracji danych, ale mogą wydać specjalne uprawnienia licencyjne dla środowisk akademickich i bibliotek uniwersyteckich. W związku z tym, przeprowadzono szerszą debatę na temat otwartego dostępu, co zaowocowało zaproponowaniem nowych zasad. W grudniu ubiegłego roku Komisja Europejska zaproponowała projekt ustawy, która umożliwi naukowcom zastosowanie metod text i data mining, jako część szerokiej aktualizacji europejskich przepisów dotyczących prawa autorskiego.
Metoda text mining
Naukowiec czytający opracowanie naukowe na temat nowego ciekawego celu terapeutycznego dla raka piersi może sprawdzić odnośniki, by uzyskać więcej informacji i wywnioskować, czy szersze badania są uzasadnione. Wezwie wtedy eksperta w dziedzinie text mining i wyjaśni kontekst wyszukiwania i jego cele. Specjalista rozpocznie pracę od ręcznego wybrania odnośników. Ważnym etapem pracy jest zbudowanie korpusu, który jest procesem wymagającym wiele czasu. Użycie zbyt małej ilości haseł na początku, może spowodować że czegoś brakuje. Dlatego najlepiej zacząć od wielu haseł i zawężać je w trakcie wyszukiwania. Wyszukiwanie danych jest łatwiejsze, kiedy naukowcy wykorzystują wspólną nomenklaturę w swoich publikacjach.
Schemat procesu obróbki danych w text miningu
Źródło: Boehringer Ingelheim Pharmaceutical
Po ustaleniu parametrów można rozpocząć wydobywanie tekstu z wielu różnych źródeł, ale zdecydowanie najbardziej popularnym źródłem jest literatura medyczna.
Naukowcy zwykle będą zainteresowani porównaniem abstraktów. Jednak czasami pełny tekst będzie niezastąpiony, jeśli użytkownik zainteresowany jest wyszukiwaniem większej liczby informacji na temat określonych materiałów i metod. Bardzo kosztowne i czasochłonne jest pobieranie artykułów pełno- tekstowych.
Internet jest przeszukiwany na podstawie wyznaczonego algorytmu wydobycia, a wyniki wyszukiwania są wyświetlane w sformatowanej tabeli z pierwotnego zapytania (lub wydobytych relacji) po lewej stronie i trafiają na prawą stronę. Istnieje również kolumna cytująca, gdzie znaleziono odnośniki.
Wtedy do pracy włącza się naukowiec. Tabela wyznacza wszystkie identyfikatory PubMed z określonych schorzeń oraz identyfikatory genów. Możliwe jest wtedy prześwietlenie danych, aby dowiedzieć się, czy określone choroby są związane z genami, o których mowa w PubMed.
Tabela wynikowa przeszukiwania metodą text mining;
Żródło: Boehringer Ingelheim Pharmaceuticals
Oprogramowanie typu text mining ułatwia pracę naukowcom, jednak jego zastosowanie wymaga także ich wysiłku, gdyż wiele czynności manualnych towarzyszy zautomatyzowanemu wydobyciu tekstu.